درباره BENN
چكيدهچندگانگي كدهاي ژنتيكي يا به عبارت ديگر وجود چند كدون براي هر اسيد آمينه، مهمترين مسالهاي است كه در ترجمه معكوس (Backtranslation) تواليهاي اسيد آمينه به توالي ژني، به كمك تكنيكهاي محاسبات نرم، با آن مواجهيم. در اين برنامه، ما از همسايههاي هر اسيد آمينه در توالي پروتئيني، به عنوان مشخصه براي پيشبيني كدون مناسب استفاده كردهايم. يكي از اشکالهاي روشهاي مشابه پيشين، استفاده از شبكه عصبي، حتي براي پيشگوئي بازهاي ثابت در توالي ژني بوده است كه در اين روش بکار رفته، به دليل اينكه خروجي، كدون است نه باز آلي، چنين مسالهاي ديگر مطرح نميباشد. در اينجا، كار پيشبيني توسط شبكههاي عصبي جمعي انجام ميشود كه يك مزيت آن نسبت به روشهاي مشابه مبتني بر شبكههاي عصبي، بكار بردن شبکههاي عصبي جداگانه به ازاي هر اسيد آمينه، همچنين تركيب كردن چند شبكه براي هر اسيد آمينه براي بالابردن قدرت پيشگوئيست. بدين ترتيب كه هر يك از شبكههاي عصبي مربوط به هر اسيد آمينه، مجموعهاي متفاوت از همسايهها را به عنوان مشخصه بكار گرفته، كدون مربوط را تعيين ميكند. در ادامه، دو مكانيزم رايگيري جهت يافتن پاسخ نهائي شبكهها با هم مقايسه شده، کاراترين آنها در اين برنامه بکار رفته است. جهت ارزيابي دقت سيستم از ژنوم E.Coli به عنوان پايگاه داده استفاده شده است و دقت پيشگويي نوکلئوتيدي با روش ارزيابي دو قسمتي (2-fold Cross Validation)، تقريبا 82 درصد ميباشد.
1. مقدمه
با شناخته شدن DNA به عنوان حافظه هر سلول زنده، تلاشهاي بسياري براي كشف تواليهاي اين رمز وراثت، شروع شد. تا كنون و با وجود عزم جهاني، ژنوم تعداد محدودي از گونهها، بطور كامل توالييابي شدهاند كه اين خود، گوياي حجم بالاي كار و نياز مبرم به روشهاي جديدتر است. در كنار روشهاي آزمايشگاهي، تكنيكهاي محاسباتي نيز با تكيه بر هزينه كم و سرعت بالاي پردازش كامپيوترهاي امروزي، سعي در هموار كردن اين مسير داشتهاند.
روند طبيعي گشودن رمزهاي ژنتيكي درون هر سلول طبق اصل اساسي بيولوژي مولكولي (Central Dogma in Molecular Biology) به اين ترتيب است كه قسمتهايي از DNA توسط مكانيزمهاي خاصي در درون سلول انتخاب و بصورت تك رشته RNA رونويسي (Transcription) ميشود. سپس اين رشته كه پليمري از 4 باز آلي A، G، C و T ميباشد (در RNA، باز T جاي خود را به باز U ميدهد)، به يك توالي 20 حرفي از اسيدهاي آمينه ترجمه (Translation) ميشود (شكل 1). البته از بين اقسام تواليهاي RNA که از DNA رونويسي ميشوند، فقط mRNA به توالي پروتئيني ترجمه ميشود و ساير انواع RNA نقشهاي ديگري در سلول دارند. مثلا tRNA، وظيفه شناسايي و چسبيدن به اسيدهاي آمينه و جابجا کردن آنها براي اتصال به توالي پروتئيني را بر عهده دارد.
در ترجمه، هر سه نوكلئوتيد (يك كدون) با يك اسيد آمينه جايگزين ميگردند. بدين ترتيب 64 كدون ممكن در توالي ژني، يک توالي از 20 اسيد آمينه ميسازند[1و2] (جدول 1).
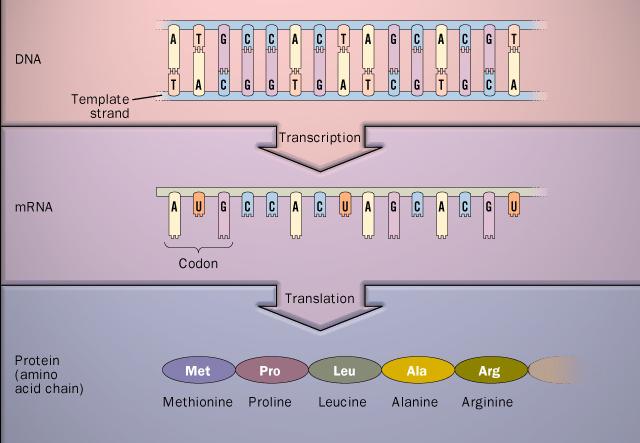
شكل 1- مسير يک طرفه از توالي ژني به توالي پروتئيني (اصل مركزي)

جدول 1 - رابطه كدونهاي استاندارد با اسيدهاي آمينه
مکانيزم ترجمه در طبيعت برگشت ناپذير است. با توجه به نياز علم بيوتکنولوژي به ترجمه معکوس در مسائلي چون طراحي پروبها (Probes) و آغازگرها (Primers) با استفاده از توالي پروتئيني [3]، بيان ژن در سيستمهاي هترولوگ (Gene Expression in Heterologous Systems) [4]، تهيه واکسنهاي DNA [5]، جستجو در کتابخانه DNA (DNA Library Screening) [3]، تحليل ساترن بلات (Southern Blot Analysis) [3] و غيره، يافتن تکنيکهايي که دقت بالاتري داشته باشند، کماکان مورد توجه است.
ترجمه هر توالي mRNA، با کدون 'AUG' که تنها کدون اسيد آمينه متيونين (Methionine) است، آغاز ميشود. اما همه اسيد آمينهها تک کدوني نيستند که بتوان به راحتي آنها را با کدون مناسب جايگزين نمود. 18 اسيد آمينه از 20 اسيد آمينه موجود، به اضافه کد توقف (Stop Codon) (کدوني که در انتهاي توالي mRNA قرار دارد، اين کد ترجمه نميشود و تنها، مکانيزم ترجمه با رسيدن به آن، متوقف ميگردد)، داراي بيش از يک کدون ميباشند که اين موضوع عمل ترجمه معکوس را دچار پيچيدگي ميکند [3].
مطالعات آماري نشان ميدهد كه فركانسهاي مشاهده هر كدون (Codon Usage) در تواليهاي مختلف ژني، اعدادي تصادفي نيستند[6و7] و تقريبا تمام ابزارهاي فعلي كه عمل ترجمه معكوس را انجام ميدهند، مانند GCG، EMBOSS، VectorNTI، EditSeq، AiO و همينطور ابزارهايي نظير Molecular Toolkit و Entelechon که از طريق شبکه اينترنت قابل دسترسي ميباشند، بر پايه اين مشخصه طراحي شدهاند. مثلا Entelechon با گرفتن يك توالي پروتئيني و درصد كدونها، هر بار تواليهاي ژني متفاوتي را برميگرداند كه فقط درصد كدونها در آنها رعايت شده است[8].
در [9] روشي نسبتا متفاوت ارائه شده است كه از قدرت تعميم شبكههاي عصبي استفاده ميكند و در اين تحقيق به عنوان مبناي کار قرار ميگيرد. در اين روش يك شبكه عصبي MLP (Multi-layer Perceptron) با ديدن هر اسيد آمينه و همسايههاي آن در توالي پروتئيني به عنوان ورودي، تمام بازهاي كدون متناظر آن اسيد آمينه را پيشگويي ميكند.
2. ترجمه معکوس با استفاده از شبکههاي عصبي
در تنها روش مبتني بر شبكههاي عصبي در ترجمه معکوس[9]، از اثر همسايهها به عنوان مشخصهاي (Feature) براي پيشگويي استفاده شده است. بدين ترتيب كه پنجرهاي 5تايي روي توالي آموزشي حركت كرده، هر 5 اسيد آمينه، بصورت كدهاي 5 بيتي يا 20 بيتي (مجموعا 25 يا 100 بيت) به عنوان ورودي به شبكه MLP داده شده است. سيستم براي 5 تا 9 لايه مخفي آزمايش شده است و خروجي آن بصورت 12 بيتي (هر 4 بيت براي يک باز)، نمايانگر كدون مربوط به اسيد آمينه واقع در وسط پنجره ميباشد. واضح است كه تمام بازها در توالي ژني، نياز به پيشگوئي ندارند و در واقع قسمتي از توانائي شبكه عصبي براي حدس زدن بازهاي ثابت توالي، هرز رفته است. اگر چه ادعا شده كه سيستم پيشنهادي، در يك مورد، %100 جايگاههاي ثابت را با بازهاي صحيح جايگزين نموده، اما اين اتفاق، هميشگي نيست.
روش ارزيابي سيستم، به اين ترتيب بوده که از تمام دادهها براي آموزش دادن شبکه استفاده شده و سپس سه توالي بطور تصادفي، به عنوان مجموعه تست، جهت تعيين دقت سيستم استفاده شده است. روشن است که با اين روش، کارايي سيستم در مواجهه با دادههايي غير از دادههاي آموزشي، مشخص نشده است. روش ارزيابي مورد استفاده در اين مقاله، بصورت ارزيابي دو قسمتي ميباشد که توانايي تعميم شبکه را، در مورد مثالهايي که قبلا با آنها مواجه نشده است، تعيين ميکند. در اين روش که در مسائلي با پايگاه داده بزرگ اعمال ميگردد، دادهها به دو قسمت مساوي تقسيم ميشوند و در دو مرحله، هر بار يکي از قسمتها به عنوان داده آموزشي و قسمت ديگر به عنوان داده تست بکار ميروند.
3. برنامه حاضر
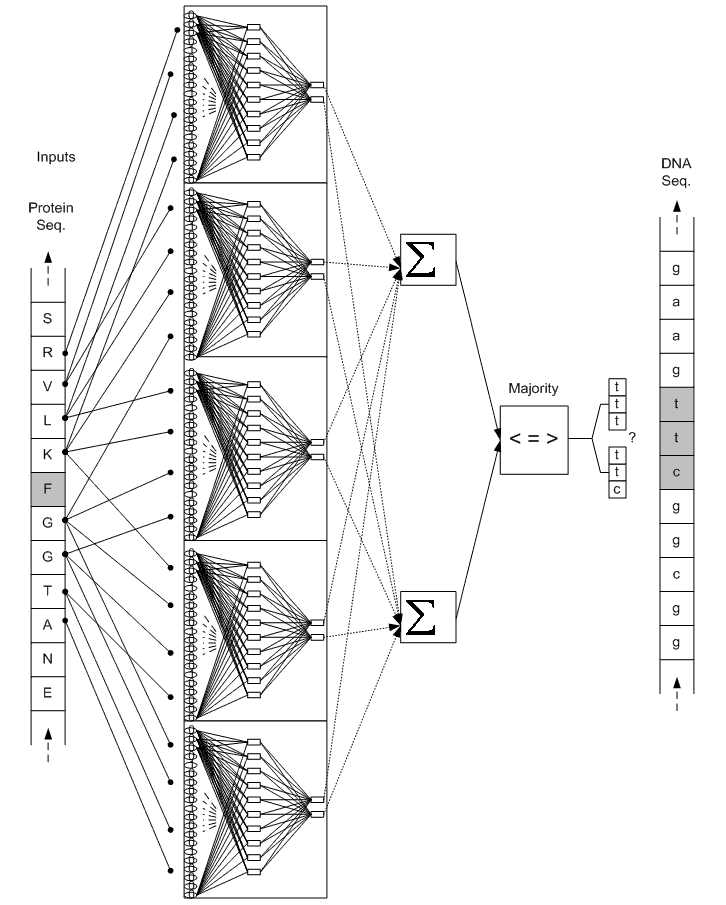
براي هر اسيد آمينه، در ابتدا 4 همسايه (از هر طرف دو همسايه)، به عنوان مشخصه در نظر گرفته شده است (شكل 2). تعداد خروجيهاي هر شبکه، به تعداد کدونهاي همان اسيد آمينه ميباشد. مثلا در شکل 2، شبکه مربوط به اسيد آمينه F نمايش داده شده است که دو خروجي آن، تعيين ميکنند کدام يک از کدونهاي ttt و ttc بايد در توالي mRNA قرار گيرند.
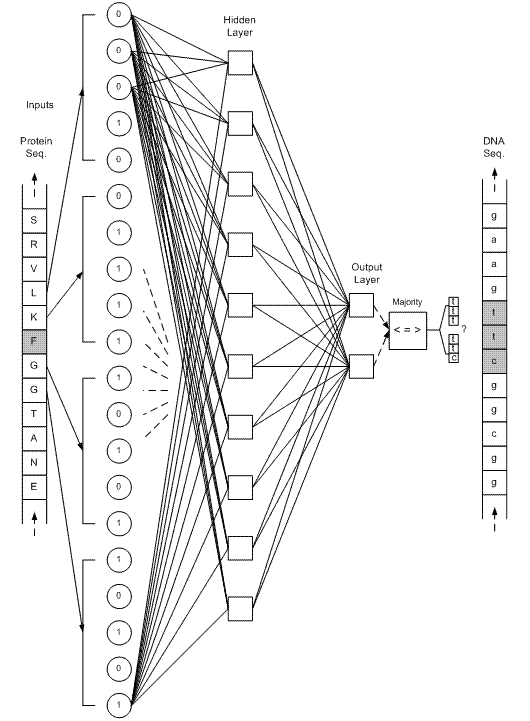
شكل 2 - در صورتيکه تعداد خروجي هر شبکه عصبي (مربوط به هر اسيد آمينه) به تعداد کدونهاي آن اسيد آمينه باشد، بازهاي ثابت در توالي mRNA، نيازي به پيشگوئي نخواهند داشت. مثلا در اين شکل، F-ANN که شبکه مربوط به اسيد آمينه F ميباشد، تنها يکي از دوکدون ttt يا ttc را انتخاب ميکند و دوجايگاه اول هميشه با باز صحيح جايگزين ميشود، ضمن اينکه در جايگاه سوم فقط يکي از دو باز c يا t قرار خواهند گرفت.
بررسي دادهها نشان ميدهد كه در برخي موارد، وروديهاي يکسان، خروجيهاي متفاوت دارند. اين موضوع اگرچه از ديد شبکه عصبي، اغتشاش (Noise) به حساب ميآيد، ولي در واقع، نشان دهنده ناكافي يا نامناسب بودن مشخصهها براي كار كلاس بندي ميباشد. اما با افزايش بيش از حد شعاع همسايگي، علاوه بر تحميل محاسبات بسيار سنگين به سيستم، با مشكل فرايادگيري (Overfitting) مواجه خواهيم شد. ترفندي كه در اينجا بكار گرفته شده است، استفاده از شبكههاي عصبي جمعي (Neural Network Ensembles) ميباشد كه هر كدام تركيبي از همسايهها را به عنوان ورودي در نظر ميگيرند. در نهايت با استفاده از روشهاي جمعبندي (Aggregation) در رايگيري، برآيند رايهاي هر مجموعه از شبكهها، خروجي را تشكيل خواهند داد.
4. شبكههاي عصبي جمعي
يادگيري جمعي، به طور ساده، به روشهايي ميگويند كه با تركيب كردن چند يادگير، كارايي كل سيستم را بالاتر ببرند[10]. مطالعات تجربي نشان دادهاند كه حل مسائل كلاس بندي و رگرسيون به كمك يادگيرهاي جمعي، اغلب دقيقتر از يادگيرهاي تكي است [11] و اخيرا نيز، روشهاي تئوري متنوعي در توجيه اثرات برخي از تكنيكهاي معمول يادگيري جمعي ارائه شدهاند [12]. ايده يادگيري جمعي، بر پايه نتيجه يک تئوري رياضي از قرن هيجدهم، به نام تئوري ژوري در زمينه علوم اجتماعي توسط Condorcet بنا نهاده شده است. اين قضيه ثابت ميکند که حکم يک هيئت، بر حکم تک تک افراد آن، ارجح است اگرتمام افراد آن هيئت، با صلاحيت باشند (يا به عبارت ديگر، احتمال صحت حکم آنها از 0.5، بيشتر باشد) [10]. اين تئوري کماکان به عنوان يک مبناي قوي براي توجيه عملکرد بهتر يادگيري جمعي نسبت به الگوريتمهايي که سعي در بالا بردن دقت يک يادگير دارند، به حساب ميآيد. همچنين تحليلهاي کلاسيک باياس-واريانس خطا نشان دادهاند که روشهاي يادگيري جمعي ميتوانند واريانس خطا و در برخي موارد هم واريانس و هم باياس خطا را کاهش دهند [13و14].
روشهاي يادگيري جمعي به دو دسته غيرمولد (Non-Generative) و مولد (Generative) تقسيم ميشوند [10]. اساس روشهاي غيرمولد، بر بکارگيري يادگيرهاي از پيش طراحي شده است و تکنيکهاي بکار رفته، سعي ميکنند برآيندي از يادگيرها را با دقتي بالاتر از هر تک يادگير، بدست آورند. در روشهاي مولد، يادگيرهاي مناسب براي حل مساله، مطابق نياز، ساخته ميشوند. برخي از روشهاي استفاده شده براي طراحي يادگيرها عبارتند از: بکار بردن دادههاي آموزشي متفاوت جهت آموزش هر کدام از يادگيرها با تقسيم مجموعه دادهها يا جمع آوري دادهها در زمانهاي متفاوت، بهره گرفتن از مشخصههاي متفاوت در آموزش هر يادگير، بکار بردن الگوريتمهاي يادگيري متفاوت، آموزش دادن ماشينهاي يادگير با طراحيهاي مختلف، آموزش دادن يادگيرها با شرايط اوليه متفاوت، بکار بردن توابع هدف مختلف و غيره [15و10و16].
کارايي روشهاي يادگيري جمعي بستگي زيادي به دقت و استقلال (Independency) يا واگرايي (Diversity) تک يادگيرها دارد. بدين ترتيب که هرچه خطاي يادگيرها، کمتر باشند و اين خطاها، همبستگي (Correlation) کمتري باهم داشته باشند، کارايي جمعي بالاتري خواهند داشت [17]. البته تجريبات اخير نشان دادهاند که هميشه يادگيرهاي مستقل بهتر از يادگيرهاي به هم وابسته نميباشند. در واقع ميتوان گفت که ميان دقت و استقلال نوعي توازن (Trade-off) وجود دارد. به اين معنا که هر چه دقت تک يادگيرها بالاتر رود، استقلال آنها کمتر ميشود [18].
5. راي گيري
روشهاي جمعبندي آرا را ميتوان با توجه به نوع يادگير، به دو دسته تقسيم نمود. دسته اول، روشهايي هستند که از آراي يادگيرهايي که خروجي آنها بصورت قبول يا رد (Accept or Reject) ميباشد، استفاده ميکنند. روش معمول در اينگونه رايگيري، پذيرش راي اکثريت (Majority) است. بدين معنا که کلاسي که يادگيرها، راي بيشتري به آن بدهند، به عنوان کلاس خروجي پذيرفته ميشود[16و19]. در اين دسته از روشها، اگر براي آرا، وزني در نظر گرفته شود، اين وزنها غالبا يا با توجه به دقت يادگير تنظيم ميشوند، يا اينکه در طي يک فرآيند يادگيري جداگانه، بدست ميآيند [20و19].
دسته دوم روشهاي جمعبندي آرا، مربوط به يادگيرهايي ميشوند که خروجي آنها، مقاديري پيوسته، عموما در فاصله [1 0] ميباشند که اين خروجي به عنوان ميزان قطعيت (Certainty) رايها، در نظر گرفته ميشود. به عنوان مثال در برخي از کارها، يک حد آستانه (Threshold) جهت اعتماد به خروجي يادگير، درنظر گرفته ميشود که اگر نرخ اطمينان کلاسي که يادگير، به آن راي ميدهد، کمتر از آن حد باشد، راي آن يادگير، رد خواهد شد. روش ديگر، محاسبه ميانگين مقدار خروجيهاي مربوط به هر کلاس و در نهايت انتخاب کلاس با بيشترين مقدار حاصل، به عنوان خروجي، ميباشد [19]. همچنين، محاسبه حاصلجمع خروجيهاي مربوط به هر کلاس و سپس، مقايسه آنها براي يافتن بيشترين مقدار حاصل، يکي ديگر از تکنيکهاي پيشنهاديست [19].
6. آزمايشها و نتايج
در ابتدا بايد براي دادههاي ورودي كد بندي مناسبي انتخاب شود. نتايج [9] نشان داده كه انتخاب كدبندي نامناسب، تاثير زيادي بر دقت نهايي خواهد داشت. در اينجا، با توجه به تعداد 20 اسيد آمينه موجود و كد توقف و همچنين كدي براي استفاده به عنوان تهي (در دو انتهاي تواليها)، 22 حالت مختلف وجود دارد كه مناسبترين كدبندي براي آن، کدي 22بيتي است كه به ازاي هر كدام از حالتها تنها يك بيت، يك و بقيه، صفر باشند. اما اين روش كدبندي به حافظه زياد و زمان اجراي طولاني نياز دارد. بنابراين به همان كد باينري 5 بيتي اكتفا شده است.
به ازاي هر اسيد آمينه در توالي پروتئيني، يك پنجره به طول 4 روي همسايهها حرکت ميکند كه از چهارمين همسايه سمت چپ، شروع و به چهارمين همسايه سمت راست، ختم ميشود (شكل 3). بدين ترتيب به ازاي هر اسيد آمينه، پنج ورودي براي پنج شبكه عصبي MLP فراهم خواهد شد. براي يادگيري شبكهها نيز، الگوريتم پس انتشار خطا (Error back propagation) بكار گرفته شده است [21]. تعداد خروجيهاي هر شبكه به تعداد كدونها ميباشد. به اين معني كه هر شبكه به ازاي هر كدون اسيد آمينه مربوط، يك مقدار به عنوان خروجي ميدهد؛ مثلا در شکل 3، هر يک از پنج شبكه مربوط به فنيل آلانين، دو خروجي دارند كه هر خروجي، ميزان قطعيت يكي از كدونهاي فنيل آلانين ميباشد (خروجيها در شکل 4 نشان داده شدهاند).
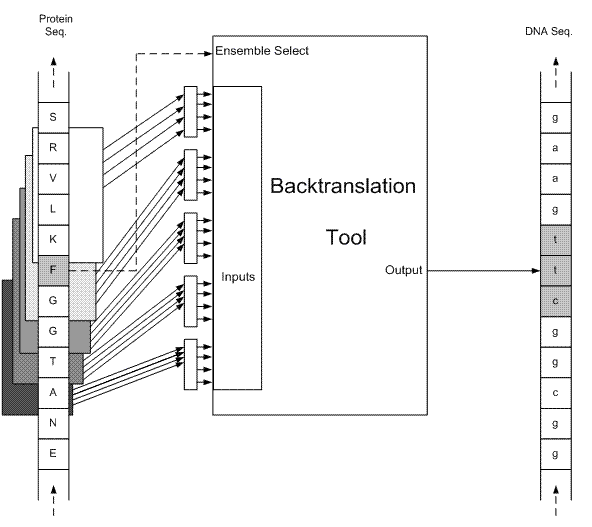
شكل 3 - نماي كلي سيستم براي فنيل آلانين (F)
مكانيزم راي گيري بکار رفته در اينجا به اين صورت بوده است که خروجيهايي از شبکهها که مربوط به يک کدون ميباشند، با هم جمع ميشوند و سپس از نتيجه، که ميتوان آنرا مجموع ميزان قطعيت شبکهها در مورد هر کدون ناميد، ماکزيمم گرفته ميشود. يعني اگر خروجيهاي شبکههاي عصبي مربوط به هر اسيد آمينه را با ![]() (jامين خروجي از شبکه iام به ازاي هر اسيد آمينه)، نشان دهيم، خروجي مجموع، طبق رابطه زير محاسبه ميشود.
(jامين خروجي از شبکه iام به ازاي هر اسيد آمينه)، نشان دهيم، خروجي مجموع، طبق رابطه زير محاسبه ميشود.
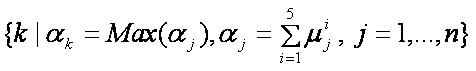
شكل 4. نمودار شبكه عصبي مربوط به اسيد آمينه F
جهت آزمايش ميزان کارائي روش فوق از ژنوم E.Coli به عنوان پايگاه داده استفاده شده است. به دليل اينكه تواليهاي با طول يكسان، برخي خصوصيات مشابه نشان ميدهند، 4287 توالي E.Coli بر اساس طول، به 10 دسته كمتر از 100 كدوني، 100 تا 200 كدوني، 200 تا 300 كدوني، ... و بيش از 900 كدوني تقسيم شدهاند. در نمودار شکل 5 نتايج مربوط به روش ارائه شده در [20] با کدبندي پنج بيتي و دادههاي E.Coli ارائه شده است. درصد کدونهاي صحيح پيشبيني شده %36.5 و بازهاي صحيح %76.39 ميباشد.
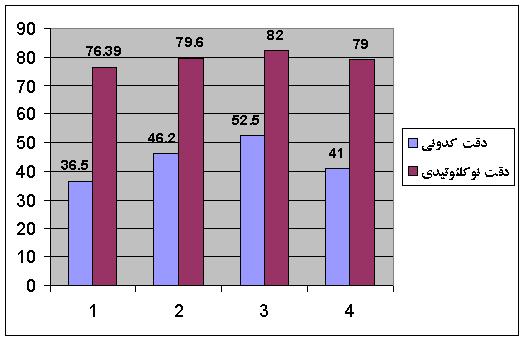
شکل 5 - مقايسه روشهاي بکار رفته مبتني بر شبکههاي عصبي با Entelechon؛ 1- دقت با استفاده از تنها يک شبکه به ازاي هر دسته از تواليها، 2- دقت يک شبکه به ازاي هر اسيد آمينه، 3- دقت 5 شبکه به ازاي هر اسيد آمينه با استفاده از شبکههاي عصبي جمعي، 4- Entelechon
همانگونه که در نمودار فوق نشان داده شده، استفاده از شبکههاي جداگانه به ازاي هر اسيد آمينه، به ميزان قابل توجهي دقت را بهبود داده است. در نهايت، جهت کم کردن اثر اغتشاش در دادههاي ورودي شبکههاي عصبي، براي هر اسيد آمينه، پنج شبکه، جمعا 95 شبكه عصبي (19 5) -18 اسيد آمينه با بيش از يک کدون به اضافه کد توقف- براي هر محدوده از طول رشته، آموزش داده شده، كارايي آنها با روش ارزيابي دو قسمتي بدست آمده است. پس از ده بار تکرار آزمايش، استفاده از شبکههاي عصبي جمعي بهترين دقت را نشان ميدهد که براي کدونها %52.5 و براي بازها %82 ميباشد (شکل 5). همانطور که در نمودار شکل 5 نشان داده شده، استفاده از يادگيري جمعي نسبت به بکارگيري تنها يک شبکه عصبي به ازاي هر اسيد آمينه، کارايي بهتري داشته است. همچنين نتايج بدست آمده با Entelechon که ابزار متداول ترجمه معکوس ميباشد، مقايسه شده است.
7. نتيجهگيري
جهت آزمايش اين برنامه، علاوه بر شکستن دادهها بر اساس طول آنها به ده قسمت، در ابتدا به ازاي هر اسيد آمينه، سيستم پيشگويي جداگانهاي در نظر گرفته شده است. سپس با استفاده از يادگيري جمعي، همسايههاي بيشتري از هر اسيد آمينه جهت پيشگويي کدون مناسب، دخالت داده شده، ضمنا اثر اغتشاش دادههاي ورودي شبکههاي عصبي تا حدي کاهش يافته است. بنا بر نتايج ارائه شده در [9] پيش بيني ميشود که كد 22 بيتي، دقت بيشتري خواهد داشت. در مورد کاهش استقلال شبکهها با بالا رفتن دقت هر کدام، که در [18] بحث شده است، با توجه به اينکه شبکهها از مشخصههاي مختلف استفاده ميکنند، پيش بيني ميشود که بالا رفتن دقت هر شبکه تاثير چنداني بر کم شدن استقلال آنها نداشته باشد. ضمنا ميتوان با افزايش تعداد شبكههاي همكار و دخالت دادن تركيبهاي بيشتر و متنوعتري از همسايهها و همچنين تغيير اندازه پنجره، نتايج بهتري بدست آورد. البته در [16] روشي براي انتخاب برخي از يادگيرها به عنوان همكار، بجاي استفاده از همه يادگيرها ارائه شده است. اگرچه در اينجا با مقايسه ميزان دقت هر شبكه نسبت به 4 شبكه همكار خود در بالا، برتري محسوسي براي هر يك از شبكهها نسبت به 4 شبكه ديگر، حاصل نشد. به عبارت ديگر در هر مجموعه، هر 5 شبكه همكار، تقريبا در يك سطح از دقت و اهميت قرار دارند و اين موضوع، دادن وزنهاي متفاوت به آراي يادگيرهاي جمعي را، منتفي ميكند.
8. منابع
[1] Clote, P., R. Backofen (2000). Computational Molecular Biology, an Introduction. Chichester: John Wiley & Sons LTD, Inc.
[2] Waterman, M.S. (1995). Introduction to Computational Biology. London: Chapman & Hall.
[3] Lodish, H., A. Berk, S. L. Zipursky, P. Matsudaira, D. Baltimore, J. E. Darnell (2003). Molecular Cell Biology. 5th ed. New York: W. H. Freeman and Company.
[4] Snyder, L., W. Champness (1997). Molecular Genetics of Bacteria. Washington, D.C.: ASM Press.
[5] Lehninger, A. L., M. M. Cox, D. L. Nelson (2000). Principals of Biochemistry. 3rd ed. New York: Worth Publishers.
[6] Karlin, S., V. Brendel (1993). "Patchiness and Correlations in DNA Sequences." Science. vol.259.pp.677-680.
[7] Peng, C., S. Buldyrev, A. Goldberger, S. Havlin, F. Sciortino, M. Simons, H. Stanley (1992). "Long-range Correlations in Nucleotide Sequences." Nature. vol.356.pp.168-170.
[8] Moreira, A. (2002). "Genetic Algorithms for the imitation of genomic styles in protein backtranslation." Theoretical Computer Science. vol.322.pp.297-312.
[9] White, G., W. Seffens (1998). "Using a neural network to backtranslate amino acid sequences." Electronic Journal of Biotechnology. vol.1(3).
[10] Valentini, G., F. Masulli (2002). "Ensembles of Learning Machines." Series Lecture Notes in Computer Sciences, Springer-Verlag. vol.2486.pp.3-19.
[11] Bauer, B., R. Kohavi (1999). "An empirical comparison of voting classification algorithms: Bagging, boosting and variants." Machine Learning. vol.36(1/2).pp.525-536.
[12] Schapire, R. E. (1999). "A brief introduction to boosting." In: 16th International Joint Conference on Artificial Intelligence. Thomas Dean (ed). pp.1401-1406.
[13] Geman, S., E. Bienenstock, R. Doursat (1992). "Neural networks and the bias-variance dilemma." Neural computation. vol.4(1). pp.1-58.
[14] Krogh, A., J. Vedelsby (1995). "Neural network ensemble, cross validation and active learning." In Advances in Neural Information Processing Systems 7. Touretzky, D. S., G. Tesauro, T. K. Leen (ed). MIT Press, Cambridge, MA. vol.7.pp.107-115.
[15] Buxton, B. F., W. B. Langdon, S. J. Barrett (2001). "Data Fusion by Intelligent Classifier Combination." Measurement and Control. vol.34(8).pp.229-234. [16] Zhou, Z., J. Wu, W. Tang (2002). "Ensembling Neural Networks: Many Could be Better Than All." Artificial Intelligence. vol.137(1/2)pp.239-263.
[17] Optiz, D. W., J. W. Shavlik (1996). "Generate Accurate and Diverse Members of a Neural Network Ensemble." In: Advances in Neural Information Processing Systems. Touretzky, D. S., M. C. Mozer, M. E. Hasselmo (ed). Denver, CO, MIT Press, Cambridge, MA. vol.8.pp.535-541.
[18] Kuncheva, L. I., et al (2000). "Is independence good for combining classifiers?." In: Proc. of 15th Int. Conf.on Pattern Recognition. Barcelona, Spain. vol.2.pp.168-171.
[19] Battiti, R., A. M. Colla (1994). "Democracy in Neural Nets: Voting Schemes for Classification." Neural Networks. vol.7(4).pp.691-707.
[20] Ishibuchi, H., T. Nakashima, T. Morisawa (1999). "Voting in fuzzy rule-based systems for pattern classification problems." Fuzzy Sets and Systems. vol.103.pp.223-238.
[21] Fausett, L. (1994). Fudamentals of Neural Networks. New Jersey: Prentice-Hall, Inc.